EIE: Efficient Inference Engine on Compressed Deep Neural Network
This paper is about energy efficient DNN architecture based on Sparse Matrix-vector Multiplication.
How to Reduce Energy
The factors of power consumption in DNN accelerator are Computation and External Memory Access. Among them, External Memory Access is the most Influential factor. In fact, Comparing the power consumption External Memory Access with Computation, 32 bit floating-point multiplication comsumes 3.7 pJ but 32 bit DRAM access consumes 640 pJ. The External Memory Access consumes 173 times more than Computation. So, we should reduce External Memory Access to reduce the power consumption.
Then, how to reduce the External Memory Access? There are so many techniques and previous researches to reduce the External Memory Access (e.g. improve reusability). This paper suggests Deep Compression to reduce the External Memory Access by reducing model size.
Deep Compression
Deep Compression (Han et al., ICLR 2016) reduces model size 35x in AlexNet by pruning, quantization and huffman coding. The power of Deep Compression is there is less accuracy loss even though the model is compressed to small size. I will summarize this paper, Deep Compression, in other post.
Sparse Matrix
This paper transforms the weight matrix to Sparse Matrix using CSC (Compressed Sparse Column) format. CSC format has 3 arrays. The one is Virtal Weight array. This array includes all of non-zero values in the weight matrix. The second one is Relative Row Index array. This array includes the values which mean how many zeros before the correspond Virtual Weight. The last one is Column Pointer array. This array includes the values pointing the index of each column.
Let’s see the example. The figure below indicates a example of matrix-vector multiplication in DNN.
Figure 2 and 3 in EIE: Efficient Inference Engine on Compressed Deep Neural Network. Han et al. ISCA 2016.
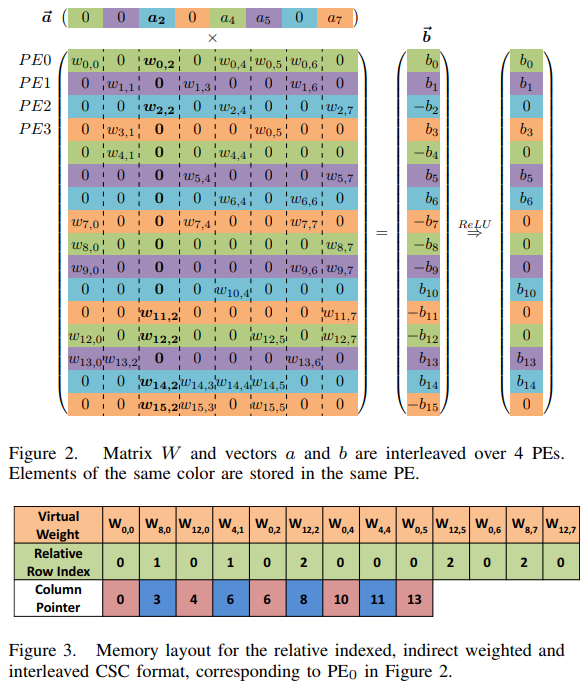
The weight matrix, the most large matrix in the center, includes many zeros.
First, we extracts non-zero values in this matrix. In the Virtual Weight array, you can see the sorted non-zero values for PE0 by column wise.
Next, we need to make index array because the non-zero values are irregular in the weight matrix. In Relative Row Index, there are values which mean index of Virtual Weight. The first value, 0, means there is no zero before w0,0. The second value, 1, means there is only 1 zero between w0,0 and w8,0 in PE0.
The last, Column Pointer indicates the pointer of Virtual Weight for each column. The first and second value, 0 and 3, mean the first column [ w0,0, w8,0, w12,0 ] occupies from index 0 to 3 - 1(i.e. 2). Let’s see the 4th and 5th value in Column Pointer array. Those values are same as 6. That means all of weight values in the 4th column are zero (i.e. there is no Virtual Weight value in the 4th column). The last value, 13, means Virtual Weight array indices are end at index 13.
Architecture
Figure 4 in EIE: Efficient Inference Engine on Compressed Deep Neural Network. Han et al. ISCA 2016.
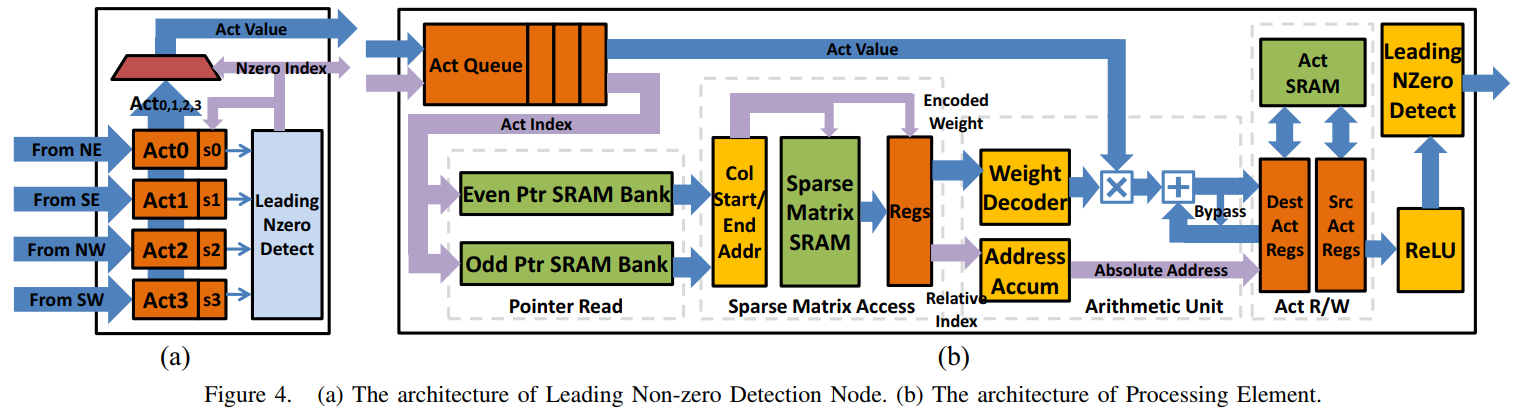
The PE (Processing Element) architecture implements to exploit Deep Compression. First, there is Leading Non-zero Detect (LND) to detect first non-zero value in the activation. Statistically, there are 70% of zero values in activation. In order to exploit sparsity of activations, we need to detect non-zero value in the activation vector. LND node broadcasts the first non-zero activation to every PE activation queue.
Second, there are couple of Ptr SRAM Bank because we always need two Column Pointers which indicate start and end of the column.
Third, the accelerator accesses to Sparse Matrix SRAM to get the non-zero weight value from Virtual Weight array. And next, the non-zero weight value encoded by 4 bit quantzation has to decode to 16 bit fixed point. The Address Accum accumulates the index value to access next weight.
After multiply and add calculation between activation and weight value, the output value is stored in the Act Regs and Act SRAM to be used in the next layer by input value.
Evaluation
Figure 6 and 7 in EIE: Efficient Inference Engine on Compressed Deep Neural Network. Han et al. ISCA 2016.
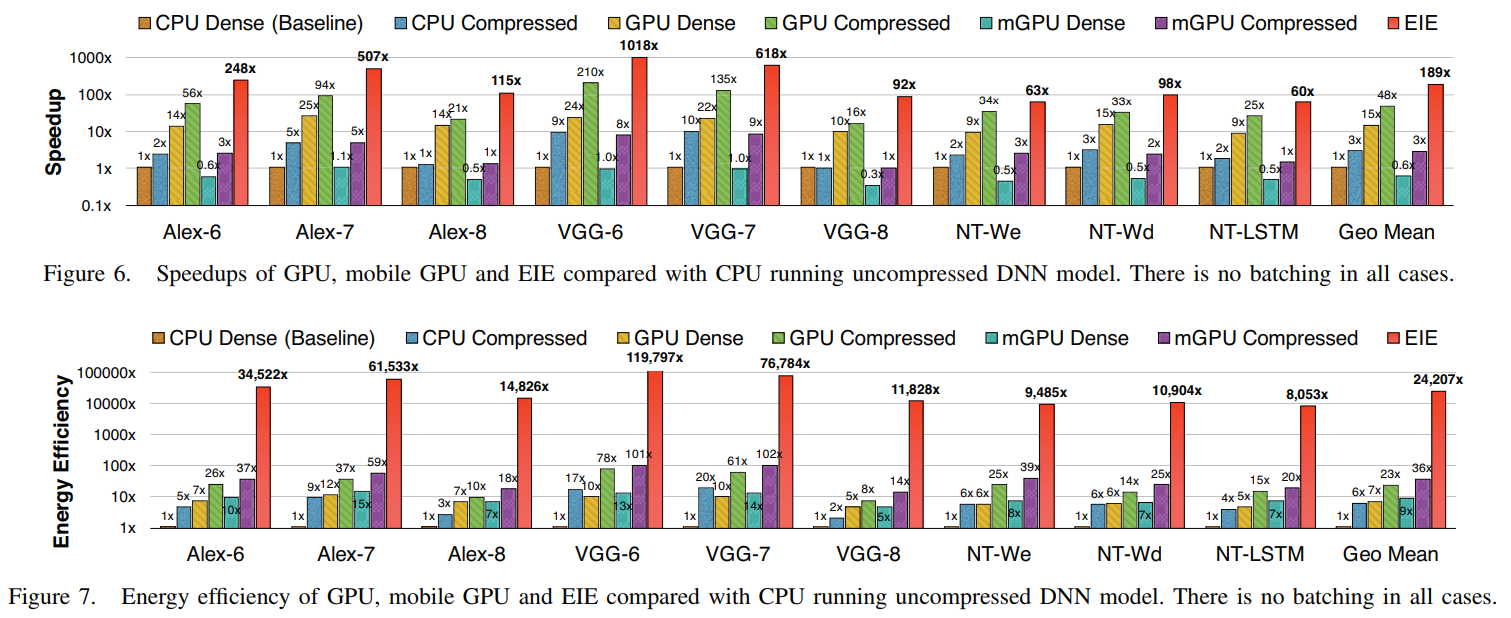
The main reasons of energy efficincy and performance improvement are below:
- Deep Compression: 35x
- DRAM access: 120x
- Activation Sparsity: 3x